Channel 是 Go 语言的核心数据结构,也是支撑 Go 高性能并发编程的重要结构。在本篇文章中,我们将从 channel 的设计原理、数据结构、发送数据、接收数据以及关闭 channel 这几个方面进行一些深入的分析,帮助大家更好地理解 channel 的工作原理。
本文源码基于 Go 1.20
CSP 模型
Go 的并发哲学
Do not communicate by sharing memory; instead, share memory by communicating.
不要通过共享内存进行通信,而应该通过通信来共享内存。
这是 Go 的并发哲学,它依赖于 CSP 模型,基于 channel 实现。
CSP 的全称是 “Communicating Sequential Processes”,这也是 1978 年 ACM 期刊中 Charles Antony Richard Hoare 写的经典同名论文。在文章中,CSP 也是一门自定义的编程语言,该语言描述了并发过程之间的交互作用。
相对于使用 sync.Mutex 这样的并发原语,虽然大多数锁的问题可以通过 channel 或者传统的锁两种方式之一解决,但是 Go 语言核心团队更加推荐使用 CSP 的方式。
数据结构
channel 的数据结构源码位于src/runtime/chan.go 中,如下所示:
// src/runtime/chan.go
type hchan struct {
qcount uint // 环形缓冲区中的元素个数
dataqsiz uint // 环形缓冲区的 size
buf unsafe.Pointer // 指向环形缓冲区的指针(只针对有缓冲的 channel)
elemsize uint16 // chan 中元素大小
closed uint32
elemtype *_type // 元素类型
sendx uint // 已发送元素在环形缓冲区中的索引
recvx uint // 已接收元素在环形缓冲区中的索引
recvq waitq // 接收等待队列
sendq waitq // 发送等待队列
lock mutex // runtime 包提供的互斥锁
}
其中,lock 是一个互斥锁,它会保护 hchan 中的所有字段,也是 channel 线程安全的保证。
等待队列使用双向链表 waitq 表示,链表中的所有元素都是 sudog 结构:
// src/runtime/chan.go
type waitq struct {
first *sudog
last *sudog
}
sudog 表示一个在等待队列中的 g . 其中存储了两个分别指向前后的 sudog 指针以构成链表。 g 与同步对象的关系是多对多的,所以一个 g 可以出现在多个等待队列上面,因此一个 g 可能有多个 sudog ,并且多个 g 可能在等待同一个同步对象,因此一个对象可能有许多 sudog . sudog 是从特殊池中分配出来的。 使用acquireSudog() 和 releaseSudog(s *sudog) 分配和释放它们。sudog 中所有字段都受到 hchan.lock 保护。
// src/runtime/runtime2.go
type sudog struct {
g *g
next *sudog
prev *sudog
elem unsafe.Pointer // 指向数据(可能指向栈)
// 这三个字段永远不会被同时访问
// 对 channel 来说,waitlink 只由 g 使用。
// 对 semaphores 来说,只有在持有 semaRoot 锁的时候才能访问这三个字段。
acquiretime int64
releasetime int64
ticket uint32
// isSelect 表示 g 是否正在参与选择
// g.selectDone 必须进行 CAS 才能在被唤醒的竞争中胜出。
isSelect bool
// success 表示 channel c 上的通信是否成功。
// 如果 goroutine 在 channel c 上传了一个值而被唤醒,则为 true;
// 如果因为 c 关闭而被唤醒,则为 false。
success bool
parent *sudog // semaRoot 二叉树
waitlink *sudog // g.waiting 列表 or semaRoot
waittail *sudog // semaRoot
c *hchan // channel
}
创建 Channel
channel 的创建如下所示:
ch := make(chan int)
在编译阶段,编译器会讲上述代码转换成 OMAKE 类型的节点,并且在类型检查阶段将其转换为 OMAKECHAN 类型。
// src/cmd/compile/internal/typecheck/typecheck.go
func typecheck1(n ir.Node, top int) ir.Node {
switch n.Op() {
default:
ir.Dump("typecheck", n)
base.Fatalf("typecheck %v", n.Op())
panic("unreachable")
// ...
case ir.OMAKE:
n := n.(*ir.CallExpr)
return tcMake(n)
// ...
}
}
// src/cmd/compile/internal/typecheck/func.go
func tcMake(n *ir.CallExpr) ir.Node {
args := n.Args
// ...
i := 1
var nn ir.Node
switch t.Kind() {
default:
base.Errorf("cannot make type %v", t)
n.SetType(nil)
return n
// ...
// channel 类型
case types.TCHAN:
l = nil
// 带缓冲 channel
if i < len(args) {
l = args[i]
i++
l = Expr(l)
l = DefaultLit(l, types.Types[types.TINT])
if l.Type() == nil {
n.SetType(nil)
return n
}
if !checkmake(t, "buffer", &l) {
n.SetType(nil)
return n
}
} else {
// 不带缓冲 channel
l = ir.NewInt(0)
}
nn = ir.NewMakeExpr(n.Pos(), ir.OMAKECHAN, l, nil)
}
if i < len(args) {
base.Errorf("too many arguments to make(%v)", t)
n.SetType(nil)
return n
}
nn.SetType(t)
return nn
}
OMAKECHAN 类型的节点最终被转换为 调用 runtime.makechan 或runtime.makechan64 函数:
// src/cmd/compile/internal/walk/expr.go
func walkExpr1(n ir.Node, init *ir.Nodes) ir.Node {
switch n.Op() {
default:
ir.Dump("walk", n)
base.Fatalf("walkExpr: switch 1 unknown op %+v", n.Op())
panic("unreachable")
case ir.OGETG, ir.OGETCALLERPC, ir.OGETCALLERSP:
return n
// ...
case ir.OMAKECHAN:
n := n.(*ir.MakeExpr)
return walkMakeChan(n, init)
// ...
}
}
// src/cmd/compile/internal/walk/builtin.go
func walkMakeChan(n *ir.MakeExpr, init *ir.Nodes) ir.Node {
fnname := "makechan64"
argtype := types.Types[types.TINT64]
// 类型检查时如果 TIDEAL 大小在 int 范围内。
// 将 TUINT 或 TUINTPTR 转换为 TINT 时出现大小溢出的情况,将在运行时在 makechan 中进行检查。
if size.Type().IsKind(types.TIDEAL) || size.Type().Size() <= types.Types[types.TUINT].Size() {
fnname = "makechan"
argtype = types.Types[types.TINT]
}
return mkcall1(chanfn(fnname, 1, n.Type()), n.Type(), init, reflectdata.MakeChanRType(base.Pos, n), typecheck.Conv(size, argtype))
}
上述代码中,默认调用makechan64 函数。如果在 make 函数中传入的 channel size 大小在 int 范围内,推荐使用 makechan() 。因为 makechan() 在 32 位的平台上更快,用的内存更少。
而runtime.makechan64 最终在判断了入参 size 是否在 int 范围之内后,也会转为runtime.makechan() 来执行,所以我们重点关注 runtime.makechan() 即可:
// src/runtime/chan.go
func makechan64(t *chantype, size int64) *hchan {
if int64(int(size)) != size {
panic(plainError("makechan: size out of range"))
}
return makechan(t, int(size))
}
// src/runtime/chan.go
func makechan(t *chantype, size int) *hchan {
elem := t.elem
// 检查数据项大小不能超过 64KB
if elem.size >= 1<<16 {
throw("makechan: invalid channel element type")
}
// 检查对齐
if hchanSize%maxAlign != 0 || elem.align > maxAlign {
throw("makechan: bad alignment")
}
// 缓冲区大小检查
mem, overflow := math.MulUintptr(elem.size, uintptr(size))
// 溢出判断
if overflow || mem > maxAlloc-hchanSize || size < 0 {
panic(plainError("makechan: size out of range"))
}
// ...
// TODO(dvyukov,rlh): Rethink when collector can move allocated objects.
var c *hchan
switch {
case mem == 0:
// 不存在缓冲区
c = (*hchan)(mallocgc(hchanSize, nil, true))
// Race 竞争检查利用这个地址来进行同步操作
c.buf = c.raceaddr()
case elem.ptrdata == 0:
// 元素非指针类型
c = (*hchan)(mallocgc(hchanSize+mem, nil, true))
c.buf = add(unsafe.Pointer(c), hchanSize)
default:
// 元素为指针类型
c = new(hchan)
c.buf = mallocgc(mem, elem, true)
}
// 设置属性
c.elemsize = uint16(elem.size)
c.elemtype = elem
c.dataqsiz = uint(size)
// lock 初始化
lockInit(&c.lock, lockRankHchan)
return c
}
makechan() 代码主要的目的就是生成 *hchan 对象。在 switch-case 中有以下三种情况:
- 当 channel 缓冲区大小为 0 时,会在堆上为 channel 开辟一段大小为 hchanSize 的内存空间。
- 当 channel 缓冲区中存储的元素不是指针类型时,会在堆上为当前 channel 和底层数组分配一段大小为 hchanSize + mem 的连续内存空间。
- 默认情况下,缓冲区元素类型为指针类型,会在堆上分别为 channel 和 缓冲区分配内存空间。
因为 channel 的创建全部调用 mallocgc() 实现,在堆上开辟了内存空间,channel 本身会被 GC 自动回收。完成内存分配之后,统一对 hchan 中的其他字段做初始化。
发送数据
向 channel 中发送数据常见代码如下所示:
ch <- 1
在编译阶段,编译器会讲上述代码转换成 OSEND 类型的节点,并最终转换为对 runtime.chansend1() 的调用。
// src/cmd/compile/internal/walk/expr.go
func walkExpr1(n ir.Node, init *ir.Nodes) ir.Node {
switch n.Op() {
default:
ir.Dump("walk", n)
base.Fatalf("walkExpr: switch 1 unknown op %+v", n.Op())
panic("unreachable")
// ...
case ir.OSEND:
n := n.(*ir.SendStmt)
return walkSend(n, init)
}
// ...
}
// src/cmd/compile/internal/walk/expr.go
func walkSend(n *ir.SendStmt, init *ir.Nodes) ir.Node {
n1 := n.Value
n1 = typecheck.AssignConv(n1, n.Chan.Type().Elem(), "chan send")
n1 = walkExpr(n1, init)
n1 = typecheck.NodAddr(n1)
return mkcall1(chanfn("chansend1", 2, n.Chan.Type()), nil, init, n.Chan, n1)
}
而 runtime.chansend1() 只是调用了runtime.chansend()函数,并传入 channel 和需要发送的数据。
// src/runtime/chan.go
func chansend1(c *hchan, elem unsafe.Pointer) {
chansend(c, elem, true, getcallerpc())
}
所以 channel 发送数据的核心实现在 runtime.chansend() 函数中,并且根据参数 block 直是否为 true 可知当前发送操作是否为阻塞的。由于runtime.chansend函数实现比较复杂,所以我们将它的代码拆为异常检查、同步发送、异步发送、阻塞发送 4 个部分进行分析。
1. 异常检查
函数一开始先进行异常检查:
// src/runtime/chan.go
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
if c == nil {
// 是否阻塞
if !block {
return false
}
gopark(nil, nil, waitReasonChanSendNilChan, traceEvGoStop, 2)
throw("unreachable")
}
if debugChan {
print("chansend: chan=", c, "\n")
}
if raceenabled {
racereadpc(c.raceaddr(), callerpc, abi.FuncPCABIInternal(chansend))
}
// 非阻塞、channel未关闭且队列已满
if !block && c.closed == 0 && full(c) {
return false
}
// 加锁
lock(&c.lock)
// channel 已经关闭
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("send on closed channel"))
}
// ...
}
// src/runtime/chan.go
func full(c *hchan) bool {
// c.dataqsiz 是不可变的,任何时候都可以安全读取
if c.dataqsiz == 0 {
return c.recvq.first == nil
}
return c.qcount == c.dataqsiz
}
如果 channel 被 GC 回收会变为 nil,向一个 nil channel 同步发送数据会发生阻塞,gopark 会引发以 waitReasonChanSendNilChan 为原因的休眠,并且之后抛出 unreachable 的 fatal error. 然后,对非阻塞的发送,要检查 channel 是否未关闭以及channel 是否可以接收数据。其次,在发送数据之前,要对整个 channel 加锁,保证线程安全。并再一次检查 channel 是否关闭,如果关闭则抛出 panic。
2. 同步发送
如果有正在阻塞等待的接收者,则直接从接收等待队列中取出第一个非空的 sudog ,并且调用send函数直接向其发送数据。
// src/runtime/chan.go
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
//...
if sg := c.recvq.dequeue(); sg != nil {
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}
//...
}
send 函数具体实现如下:
// src/runtime/chan.go
func send(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
// ...
if sg.elem != nil {
sendDirect(c.elemtype, sg, ep)
sg.elem = nil
}
gp := sg.g
unlockf()
gp.param = unsafe.Pointer(sg)
sg.success = true
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
goready(gp, skip+1)
}
函数执行可以分为 2 个部分:
- 调用
runtime.sendDirect()函数,将数据直接复制到接收变量的内存地址上。 - 调用
runtime.goready()函数将等待接收的阻塞 goroutine 的状态改为 Grunnable ,并且把该 goroutine 放到发送方所在处理器 p 的 runnext 上等待执行,该处理器 p 下一次调度时会立刻唤醒数据的接收方。
其中,goready() 具体实现如下:
// src/runtime/proc.go
func goready(gp *g, traceskip int) {
systemstack(func() {
ready(gp, traceskip, true)
})
}
func ready(gp *g, traceskip int, next bool) {
// ...
// status is Gwaiting or Gscanwaiting, make Grunnable and put on runq
casgstatus(gp, _Gwaiting, _Grunnable)
runqput(mp.p.ptr(), gp, next)
wakep()
releasem(mp)
}
casgstatus()函数的作用是修改当前 goroutine 的状态,runqput 的作用是把接收方 g 绑定到 p 本地可运行的队列中,此处 next 为 true,就是将 g 插入到 runnext 中 ,等待下一次调度就可以立即运行。这样虽然 goroutine 保证了线程安全,但是在读取数据方面会比数组慢一些,也就是说向 channel 中发送数据后并不能立即从接收方获取到。
3. 异步发送
如果创建的 channel 包含缓冲区,当接受者队列为空并且 channel 缓冲区中的数据没有装满时,就会执行异步发送的逻辑:
// src/runtime/chan.go
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
//...
if c.qcount < c.dataqsiz {
qp := chanbuf(c, c.sendx)
if raceenabled {
racenotify(c, c.sendx, nil)
}
typedmemmove(c.elemtype, qp, ep)
c.sendx++
if c.sendx == c.dataqsiz {
c.sendx = 0
}
c.qcount++
unlock(&c.lock)
return true
}
//...
}
这里首先调用chanbuf() 计算下一个可以存储数据的位置,然后调用typedmemmove() 将发送的数据拷贝到缓冲区 buf 中。拷贝完成后,重新计算发送索引 sendx 以及 qcount 的值。这里 buf 是一个环形的数组,所以当 sendx 和 数组大小相等时,sendx 会重新回到数组开始的位置。
4. 阻塞发送
当没有接受者可以处理 channel 中的数据,并且没有缓冲区或者缓冲区已满时,向 channel 中发送数据会被阻塞,具体执行的代码如下所示:
// src/runtime/chan.go
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
//...
if !block {
unlock(&c.lock)
return false
}
gp := getg() // @1
mysg := acquireSudog() // @2
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
mysg.elem = ep
mysg.waitlink = nil
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.waiting = mysg
gp.param = nil
c.sendq.enqueue(mysg) // @3
gp.parkingOnChan.Store(true) // @4
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanSend, traceEvGoBlockSend, 2) // @5
KeepAlive(ep) // @6
// ...
}
- 执行
runtime.getg()获取当前 goroutine 的指针,用于绑定给一个 sudog。 - 执行
runtime.acquireSudog()获取一个 sudog(可能是新建的 sudog,也有可能是从缓存中获取的),并且设置此次发送的数据和状态,比如当前 goroutine 的指针,发送的 channel,是否在 select 中和带发送数据的内存地址等。 - 将刚刚获取并处理过的 sudog 加入到发送等待队列。
- 设置一个原子信号,声明当前 goroutine 还停在某个 channel 上面。在 g 状态变更与设 activeStackChans 状态这两个时间点之间的时间窗口进行栈收缩是不安全的,所以需要设置这个原子信号。
- 调用
runtime.gopark()挂起当前 goruntine ,挂起原因为 waitReasonChanSend,阻塞等待 channel。 - 最后,调用
KeepAlive()函数,确保发送的值保持活动状态,直到接收者将其复制出来。sudog有一个指向堆栈对象的指针,但 sudog 不被认为是堆栈追踪器的根。发送的数值是分配在堆上,这样就可以避免被 GC 回收。
chansend 最后的逻辑是当 goroutine 唤醒以后,解除阻塞的状态:
// src/runtime/chan.go
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
//...
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
gp.waiting = nil
gp.activeStackChans = false
closed := !mysg.success
gp.param = nil
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
mysg.c = nil
releaseSudog(mysg)
if closed {
if c.closed == 0 {
throw("chansend: spurious wakeup")
}
panic(plainError("send on closed channel"))
}
return true
}
gorountine 被唤醒后,会完成对 channel 的阻塞数据发送,然后进行基本的数据检查,解除 channel 的绑定并调用releaseSudog()函数释放 sudog。
chansend()函数最后返回 true,表示此次已经成功向 channel 发送了数据。
5. 小结
对于向 channel 发送数据的代码已经完成分析,下面做一个小结:
- 向已经关闭的 channel 中发送数据,会产生 panic。
- 如果当前 channel 的 recvq 上存在等待的 g,那么会直接将数据发送给当前 g 并且将其设置为下一个要被调度的 g。
- 如果 channel 存在未满的缓冲区,则直接将数据写入缓冲区 sendx 所在的位置。
- 如果不满足以上两种情况,则会获取一个 sudog 结构,并设置好其属性,将其加入 channel 的 sendq 等待队列中,挂起当前 goroutine ,等待缓冲区有位置或者有其他 goroutine 从 channel 中接收数据时被调度器唤醒。
发送数据的过程中包含了 2 次会触发 goroutine 调度的时机:
- 当接收等待队列存在 sudog 可以直接接收数据时,执行
goready()函数,将接收等待队列的 goruntine 设置处理器的 runnext 属性,将其状态改为 Grunnable ,等待下次调度便立即运行。 - 当 channel 阻塞时,将自己加入 channel 的 sendq 发送等待队列,并执行
gopark()函数,阻塞当前 gorountine,让出 cpu 的使用权。
接收数据
从 channel 中接收数据常见代码如下所示:
// 将结果赋值给变量 v
v := <-ch
// comma ok 风格
v, ok := <-ch
在编译阶段,编译器会讲上述代码转换成 ORECV 类型的节点。第二种方式在类型检查阶段会被转换为 OAS2RECV 类型。
与上面发送数据源码分析方式类似,如下图所示,这两种类型首先会被转为对runtime.chanrecv1() 和 runtime.chanrecv2()的调用,并且最终转换为对runtime.chanrecv()的调用。
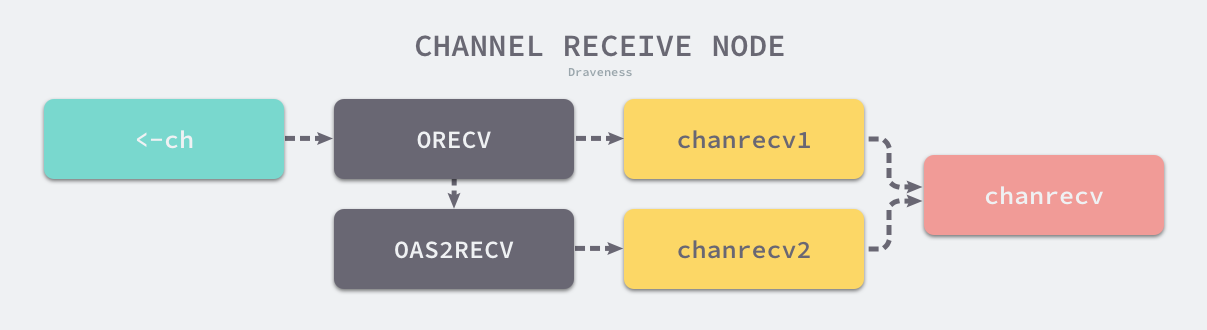
// src/runtime/chan.go
// go:nosplit
func chanrecv1(c *hchan, elem unsafe.Pointer) {
chanrecv(c, elem, true)
}
// go:nosplit
func chanrecv2(c *hchan, elem unsafe.Pointer) (received bool) {
_, received = chanrecv(c, elem, true)
return
}
所以 channel 发送数据的核心实现在 runtime.chanrecv() 函数中,并且根据参数 block 直是否为 true 可知当前发送操作是否为阻塞的,同样由于runtime.chanrecv()函数实现比较复杂,所以我们将它的代码拆为异常检查、同步接收、异步接收、阻塞接收 4 个部分进行分析。
1.异常检查
runtime.chanrevc()函数一开始是进行异常检查:
// src/runtime/chan.go
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
if debugChan {
print("chanrecv: chan=", c, "\n")
}
if c == nil {
if !block {
return
}
// 阻塞模式,挂起等待
gopark(nil, nil, waitReasonChanReceiveNilChan, traceEvGoStop, 2)
throw("unreachable")
}
// Fast path: check for failed non-blocking operation without acquiring the lock.
// 非阻塞并且channel为空
if !block && empty(c) {
if empty(c) {
// The channel is irreversibly closed and empty.
if raceenabled {
raceacquire(c.raceaddr())
}
if ep != nil {
typedmemclr(c.elemtype, ep)
}
return true, false
}
}
//...
}
// src/runtime/chan.go
func empty(c *hchan) bool {
// c.dataqsiz 是不可变的
if c.dataqsiz == 0 {
return atomic.Loadp(unsafe.Pointer(&c.sendq.first)) == nil
}
return atomic.Loaduint(&c.qcount) == 0
}
如果 channel 被 GC 回收会变为 nil,从一个 nil channel 同步接收数据会发生阻塞,gopark 会引发以 waitReasonChanReceiveNilChan 为原因的休眠,并且之后抛出 unreachable 的 fatal error. 然后,对非阻塞的发送,要检查 channel 是否为空,如果 channel 为空,那么就会清除 ep 中的数据并且立即返回。这里总共检查了两次 empty(),因为第一次检查时, channel 可能还没有关闭,但是第二次检查的时候关闭了,在两次检查之间可能有待接收的数据到达了。所以需要两次 empty() 检查。
2.同步接收
如果有正在阻塞等待的发送者,则直接从接收等待队列中取出第一个非空的 sudog ,并且调用recv函数直接向其发送数据。
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
lock(&c.lock)
if c.closed != 0 {
// 已关闭并且没有数据
if c.qcount == 0 {
if raceenabled {
raceacquire(c.raceaddr())
}
unlock(&c.lock)
if ep != nil {
// 清除ep指针
typedmemclr(c.elemtype, ep)
}
return true, false
}
} else {
// 未关闭,send queue中有等待的writer,writer出队,并调用recv函数
// Just found waiting sender with not closed.
if sg := c.sendq.dequeue(); sg != nil {
recv(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true, true
}
}
}
runtime.recv() 函数的逻辑如下所示:
func recv(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
// 不带缓冲区
if c.dataqsiz == 0 {
if raceenabled {
racesync(c, sg)
}
if ep != nil {
// copy data from sender
recvDirect(c.elemtype, sg, ep)
}
} else {
// 带缓冲区
qp := chanbuf(c, c.recvx)
if raceenabled {
racenotify(c, c.recvx, nil)
racenotify(c, c.recvx, sg)
}
// copy data from queue to receiver
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
// copy data from sender to queue
// 将 sender 的数据拷贝到这个槽中
typedmemmove(c.elemtype, qp, sg.elem)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.sendx = c.recvx // c.sendx = (c.sendx+1) % c.dataqsiz
}
sg.elem = nil
gp := sg.g
unlockf()
gp.param = unsafe.Pointer(sg)
sg.success = true
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
goready(gp, skip+1)
}
- 如果ch不带缓冲区的话,直接调用
runtimne.recvDirect函数将 writer 的sg.elem数据拷贝到接收方 ep. - 如果带缓冲区的话,此时缓冲区肯定满了,那么就从缓冲区队列头部取出数据拷贝至接收方 ep,然后将 writer 的
sg.elem数据拷贝到缓冲区中。 - 最后唤醒
writer(g)
3.异步接收
当 channel 的缓冲区已经包含数据时,从 channel 中接收数据会直接从缓冲区 recv 的索引位置取出数据进行处理:
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
// ...
if c.qcount > 0 {
// Receive directly from queue
qp := chanbuf(c, c.recvx)
if raceenabled {
racenotify(c, c.recvx, nil)
}
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
typedmemclr(c.elemtype, qp)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.qcount--
unlock(&c.lock)
return true, true
}
// 不阻塞
if !block {
unlock(&c.lock)
return false, false
}
// ...
}
如果接收数据的内存地址不为空,那么就会使用runtime.touedmemmove() 函数将缓冲区的数据复制到内存中,然后调用runtime.typedmemclr()函数清除队列中的数据,并且挪动 revcx 的指针位置(如果移动到了环形队列的队尾,下标需要回到队头),减少 count 计数器,并且释放掉占有的锁。
4.阻塞接收
当 channel 的发送队列中不存在等待的 goroutine,并缺缓冲区也没有数据是,从 channel 中接收数据的操作就会进入阻塞接收的阶段:
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
// 阻塞且缓冲区中没有数据
// 拿到当前的goroutine
gp := getg() // @1
// 获取一个sudog
mysg := acquireSudog() // @2
// sudog 关联
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
// No stack splits between assigning elem and enqueuing mysg
// on gp.waiting where copystack can find it.
mysg.elem = ep
mysg.waitlink = nil
gp.waiting = mysg
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.param = nil
// 入队
c.recvq.enqueue(mysg) // @3
// Signal to anyone trying to shrink our stack that we're about
// to park on a channel. The window between when this G's status
// changes and when we set gp.activeStackChans is not safe for
// stack shrinking.
gp.parkingOnChan.Store(true) // @4
// 协程挂起,等待唤醒
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanReceive, traceEvGoBlockRecv, 2) // @5
}
- 执行
runtime.getg()获取当前 goroutine 的指针,用于绑定给一个 sudog。 - 执行
runtime.acquireSudog()获取一个 sudog(可能是新建的 sudog,也有可能是从缓存中获取的),并且关联到当前的 guroutine。 - 将刚刚获取并处理过的 sudog 加入到接收等待队列。
- 设置一个原子信号,声明当前 goroutine 还停在某个 channel 上面。在 g 状态变更与设 activeStackChans 状态这两个时间点之间的时间窗口进行栈收缩是不安全的,所以需要设置这个原子信号。
- 调用
runtime.gopark()挂起当前 goruntine ,挂起原因为waitReasonChanReceive,阻塞等待 channel。
上面这段代码与 chansend() 中阻塞发送几乎完全一致,区别在于最后一步没有 KeepAlive(ep)。因为等待的 goroutine ep 中是没有数据需要去保活的。
chanrecv 最后的逻辑是当 goroutine 唤醒以后,解除阻塞的状态:
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
gp.waiting = nil
gp.activeStackChans = false
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
success := mysg.success
gp.param = nil
// sudog 解除关联
mysg.c = nil
releaseSudog(mysg)
return true, success
}
gorountine 被唤醒后,会完成对 channel 的阻塞数据接收。接收完最后进行基本的参数检查,解除 channel 的绑定并释放 sudog
5.小结
对于从 channel 中接收数据的代码已经完成分析,下面做一个小结:
- 从已经关闭的 channel 中读取数据,会直接返回 channel 中类型的默认零值。
- 如果当前 channel 的 sendq 上存在等待的 g,那么会将 recvx 索引所在的数据复制到接收变量所在的内存空间,并将 sendq 队列中 goroutine 中的数据复制到缓冲区。
- 如果 channel 缓冲区中包含数据,则直接读取recvx 索引对应的数据。
- 如果不满足以上两种情况,则会获取一个 sudog 结构,并设置好其属性,将其加入 channel 的 recvq 等待队列中,挂起当前 goroutine 等待调度器的唤醒。
接收数据的过程中包含了 2 次会触发 goroutine 调度的时机:
- 当 channel 为 nil 时,执行
gopark()挂起当前 goroutine - 当 channel 缓冲区为空,并且不存在发送者时,channel 发生阻塞,执行
gopark()将 g 阻塞,让出 cpu 的使用权并等待调度器的调度。
关闭 Channel
关闭 channel 常见代码如下所示:
close(ch)
在编译阶段,编译器会讲上述代码转换成 OCLOSE 类型的节点,并且最终转换为对runtime.closechan()函数的调用:
func closechan(c *hchan) {
if c == nil {
panic(plainError("close of nil channel"))
}
// 加锁
lock(&c.lock)
if c.closed != 0 {
// 已经关闭的channel
unlock(&c.lock)
panic(plainError("close of closed channel"))
}
if raceenabled {
callerpc := getcallerpc()
racewritepc(c.raceaddr(), callerpc, abi.FuncPCABIInternal(closechan))
racerelease(c.raceaddr())
}
// 设置关闭标记位
c.closed = 1
// 1. 申明一个存放g的list,用于存放在等待队列中的groutine
var glist gList
// 2. 获取所有在recvq里面的协程
// release all readers
for {
sg := c.recvq.dequeue()
if sg == nil {
break
}
if sg.elem != nil {
typedmemclr(c.elemtype, sg.elem)
sg.elem = nil
}
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
gp := sg.g
gp.param = unsafe.Pointer(sg)
sg.success = false
if raceenabled {
raceacquireg(gp, c.raceaddr())
}
glist.push(gp)
}
// 3. 获取所有在sendq里面的协程
// release all writers (they will panic)
for {
sg := c.sendq.dequeue()
if sg == nil {
break
}
sg.elem = nil
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
gp := sg.g
gp.param = unsafe.Pointer(sg)
sg.success = false
if raceenabled {
raceacquireg(gp, c.raceaddr())
}
glist.push(gp)
}
unlock(&c.lock)
// Ready all Gs now that we've dropped the channel lock.
// 4.唤醒所有的glist中的goroutine
for !glist.empty() {
gp := glist.pop()
gp.schedlink = 0
goready(gp, 3)
}
}
关闭 channel 的过程主要可以分为以下几个阶段:
- 异常检查:当 Channel 是一个 nil 或者是一个已经关闭的 channel 时,会发生 panic。
- 分别获取 recvq 和 sendq 中的 goroutine,一并放入 glist 队列中。
- 唤醒 glist 中的所有 goroutine,等待调度器的调度。